


















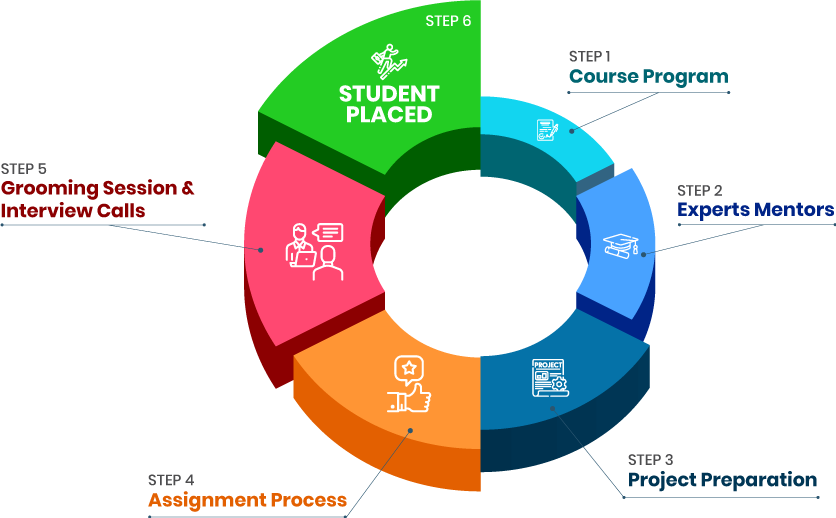
 Career Transition
Career Transition Career Gap
Career Gap Placement Activities
Placement Activities Placement Drives
Placement Drives Latest Hiring
Latest Hiring











Course Design By
Nasscom & Wipro
Master Databricks in Noida with hands-on training in big data, Spark, cloud analytics & real projects.
In collaboration with

Online/Offline
Format
LMS
Life Time Access
we train you to get hired.
Learn how large companies process millions of records per second
Understand real-time and batch data pipelines
Work on cloud-based Databricks environments
Build production-level data workflows
Handle structured and unstructured data systems
Learn system-level thinking, not just coding

Distributed Computing with help of Apache Spark Engine within Databricks
Creation and maintenance of ETL Pipelines in large scale data system
Delta Lake Versioning, Reliability and Storage optimization
Real-time Data processing through Structured Streaming
Building secure Authentication layers for Data Access systems
Cloud Integration practices in Azure and AWS Databricks
Job scheduling, Monitoring, Failure Recovery Systems in Databricks
Preparation of Data Engineering interviews scenario
Live Databricks workspace
Hands-on experience with pipeline creation with Spark and Delta Lake
Case studies based on cloud data systems used in industries
Session on pipeline debugging
Data performance tuning
Hands-on experience on real streaming and batch datasets
Cloud deployment simulation for Azure and AWS
Coding and architecture assessment for future careers
Graduates from any technical or non-technical background
Freshers aiming for data engineering or analytics roles
Working IT professionals moving into cloud or big data roles
Basic understanding of logic and problem-solving is enough
No deep programming knowledge required at entry level
Flexible batches for working professionals and students
Step-by-step learning for non-coding background learners
Extra support provided for slow learners and career switchers
Demand in cloud data engineering roles is rapidly increasing
Used widely in fintech, healthcare, e-commerce, and AI industries
Required for real-time analytics and decision systems
Used in AI model training pipelines and data lakes
Strong demand in product-based companies and SaaS platforms
Opportunities in India and global remote data engineering jobs
Growing use in automation, ML pipelines, and big data systems
Long-term career stability in cloud data engineering domain
Big data fundamentals
Distributed system basics
Introduction to Databricks environment
Apache Spark architecture
RDD, DataFrame, and Dataset concepts
Spark execution flow understanding
Data ingestion and transformation
ETL pipeline creation
Batch processing systems
Delta Lake architecture
Data versioning and time travel
Data reliability and storage optimization
Streaming data processing
Real-time pipeline building
Event-based data systems
Cloud integration (Azure / AWS Databricks)
Job scheduling and automation
CI/CD for data pipelines
Capstone project
End-to-end pipeline design
Real-world system simulation
Interview preparation and architecture discussion
Databricks certified data engineer preparation
Apache Spark certification guidance
Cloud data engineering certification mapping
Project-based certification evaluation
Mock tests based on real exam patterns
Resume-ready project portfolio creation
Technical interview simulation rounds
Freshers typically earn 4 to 10 LPA in India
Higher packages for strong cloud + Spark + SQL skills
Big data engineers get faster salary growth compared to general IT roles
Project-based portfolios increase interview selection chances
Freelance and remote job opportunities also available
Growth increases significantly with real-time pipeline experience
Strong demand in SaaS and cloud product companies
Junior Data Engineer to Senior Data Engineer roles
Transition into Cloud Architect or Data Architect roles
Move into ML pipeline and AI infrastructure engineering
Work in distributed system design and optimization roles
Growth into technical leadership positions
Opportunities in consulting and enterprise architecture
Possibility to build independent data products or startups
Continuous learning path in evolving cloud technologies
Real-world project-based training model
Industry-level Databricks and Spark labs
Strong focus on cloud-native architecture
Interview-focused technical preparation
Regular coding and system design practice
Mentorship from working professionals
Updated syllabus aligned with 2026 industry needs
Placement and career guidance support
we train you to get hired.
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy
Course Design By
Nasscom & Wipro
Course Offered By
Croma Campus
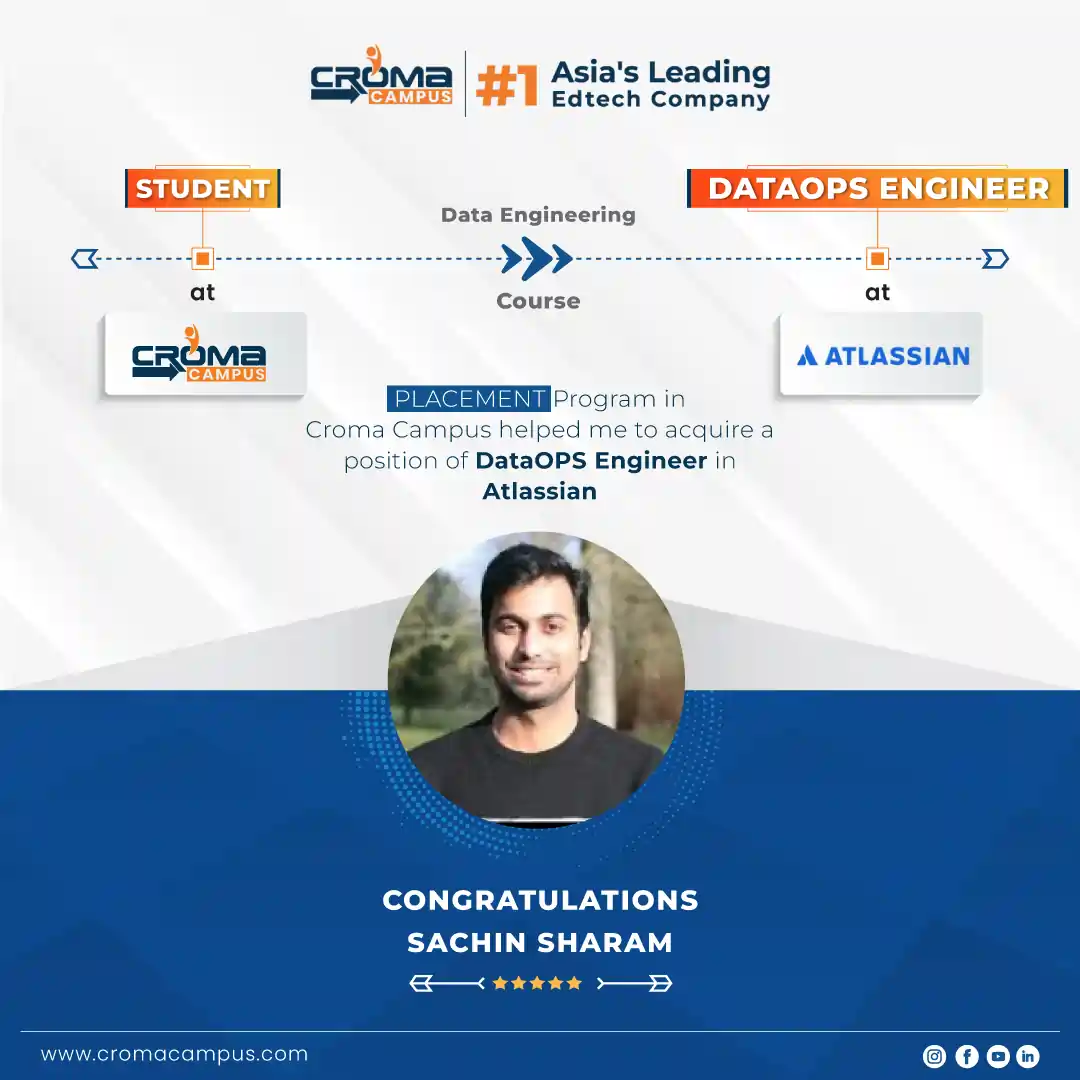
Stories
success
inspiration
career upgrade
career upgrade
career upgrade
career upgrade
You will get certificate after
completion of program
You will get certificate after
completion of program
You will get certificate after
completion of program
in Collaboration with

Empowering Learning Through Real Experiences and Innovation
we train you to get hired.
Phone (For Voice Call):
+91-828 706 0032WhatsApp (For Call & Chat):
+91-828 706 0032Get a peek through the entire curriculum designed that ensures Placement Guidance
Course Design By
Course Offered By
Ready to streamline Your Process? Submit Your batch request today!
Yes, learners work on real-time data pipelines, streaming systems, and cloud-based ETL projects.
No deep coding is required. Basic logic understanding is enough to start.
Yes, training includes Azure and AWS integration with Databricks environments.
Yes, Spark is one of the core technologies covered in depth including architecture and execution flow.
Yes, Databricks skills are highly in demand for cloud data engineering and AI pipeline roles.

Highest Salary Offered
Average Salary Hike
Placed in MNC’s
Year’s in Training

fast-tracked into managerial careers.
Get inspired by their progress in the
Career Growth Report.
FOR QUERIES, FEEDBACK OR ASSISTANCE
Best of support with us

Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy


For Voice Call
+91-971 152 6942For Whatsapp Call & Chat
+91-9711526942Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!











.webp)























































.webp)













































































.webp)






















.webp)
.webp)

.png)















