


















 Career Transition
Career Transition Career Gap
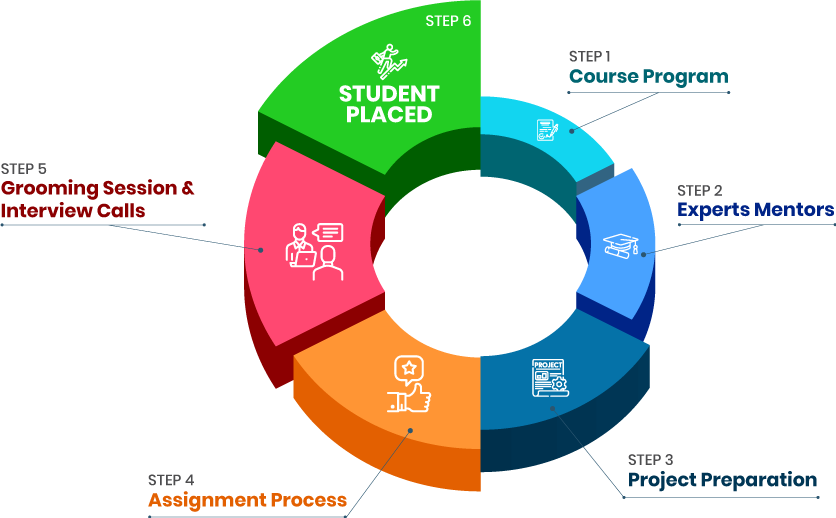
Career Gap Placement Activities
Placement Activities Placement Drives
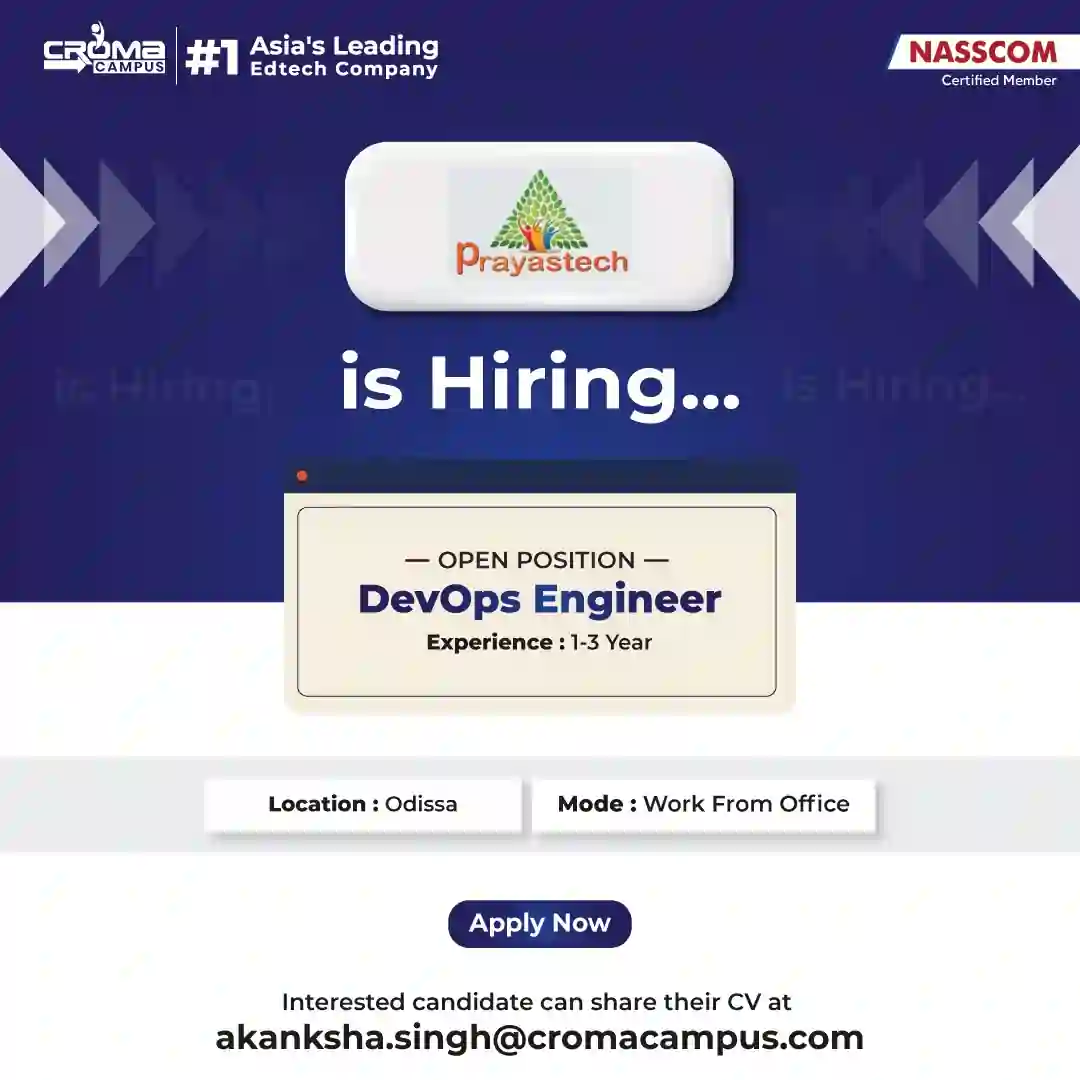
Placement Drives Latest Hiring
Latest Hiring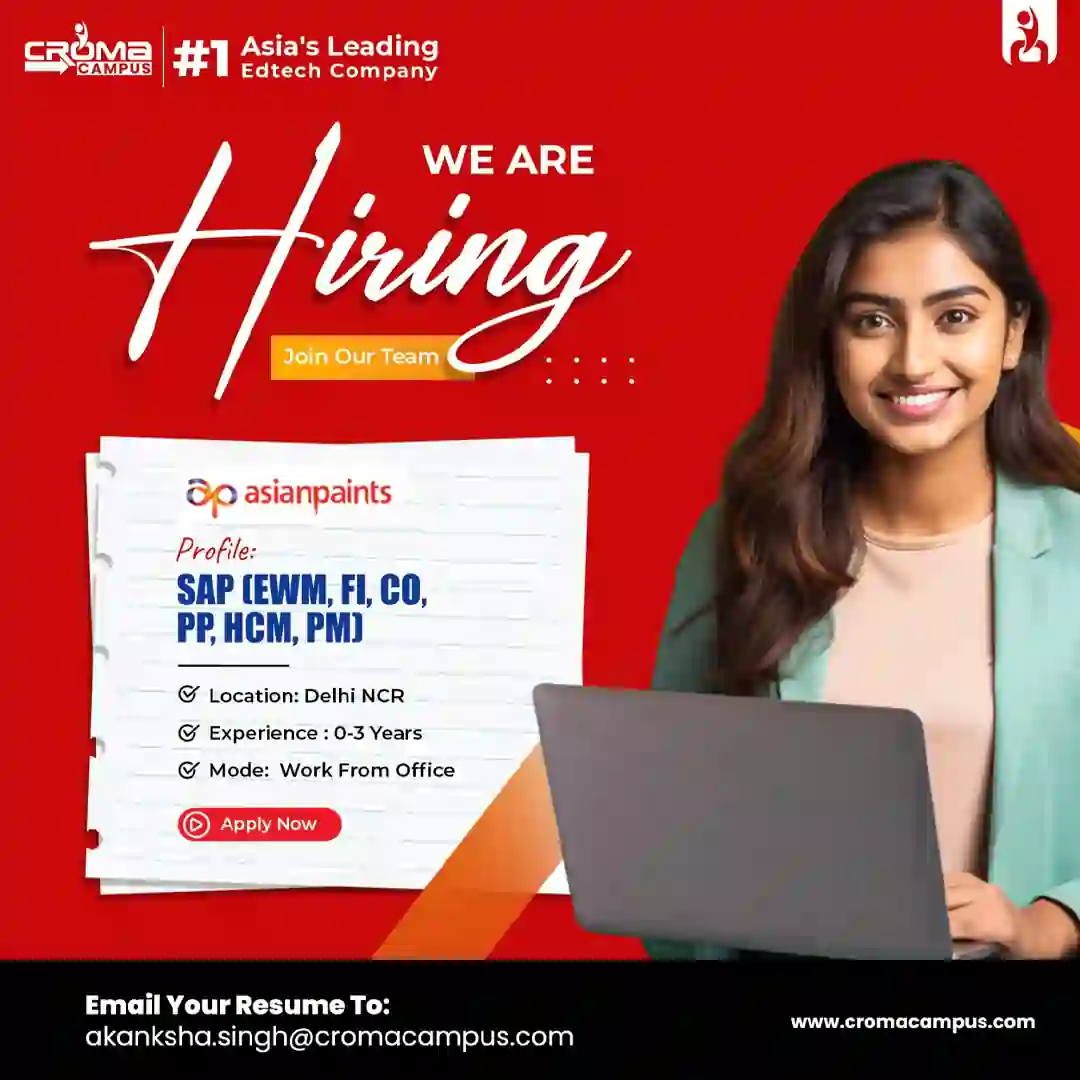










Course Design By
Nasscom & Wipro
Master Databricks Course in Gurgaon with hands-on training in big data, Spark, cloud analytics, and AI tools.
In collaboration with

Online/Offline
Format
LMS
Life Time Access
we train you to get hired.
Learn how companies process huge amounts of data
Understand batch and real-time data pipelines
Work on cloud-based Databricks environments
Build practical ETL workflows
Learn structured and unstructured data handling
Understand distributed systems in simple ways
Work on Spark-based processing systems
Learn practical cloud engineering concepts

Learn distributed computing using Apache Spark
Build ETL pipelines for large-scale systems
Understand Delta Lake storage optimization
Learn real-time streaming data processing
Understand Azure and AWS cloud integration
Learn workflow automation and scheduling
Practice pipeline monitoring and debugging
Prepare for technical interviews in data engineering
Learn practical cloud data engineering concepts
Understand real-world system behavior
Live Databricks workspace practice
Spark and Delta Lake hands-on projects
Real-time ETL pipeline development
Industry-based assignments and case studies
Pipeline debugging sessions
Data performance optimization practice
Streaming and batch processing projects
Azure and AWS cloud practice
Coding and architecture assessments
Real-world workflow understanding
Technical and non-technical graduates
Freshers searching for IT careers
Working professionals changing domains
Software developers moving into big data
Data analysts learning cloud engineering
Students interested in AI and analytics systems
Learners with basic logical understanding
Career switchers from other industries
Banking - Transaction and fraud analysis
Healthcare - Patient data management
E-commerce - Customer behavior analytics
Telecom - Network monitoring systems
AI Companies - Machine learning pipelines
SaaS Companies - Cloud analytics platforms
Cloud data engineering jobs
Big data engineering roles
Analytics infrastructure jobs
Real-time data processing work
Remote global job opportunities
Cloud automation projects
Product-based company roles
Long-term stable technology careers
Introduction to big data systems
Distributed systems basics
Databricks workspace introduction
Understanding data engineering flow
Basics of cloud-based processing systems
Spark architecture understanding
RDD, DataFrame, and Dataset concepts
Spark execution flow
Driver and executor concepts
Spark memory management basics
Data ingestion methods
ETL workflow creation
Batch data processing systems
Data transformation concepts
Pipeline optimization basics
Delta Lake architecture
Data versioning methods
Time travel concepts
Storage optimization techniques
Reliability and consistency basics
Structured streaming basics
Real-time pipeline development
Event-driven processing systems
Streaming dataset handling
Live data processing concepts
Azure Databricks integration
AWS Databricks setup
Job scheduling systems
Workflow automation methods
CI/CD pipeline basics
End-to-end project development
Real industry workflow simulation
Resume preparation support
Technical interview practice
System design discussions
Architecture-level understanding
Databricks certification preparation
Apache Spark certification guidance
Mock tests and assessment sessions
Project-based evaluations
Resume-ready project portfolio
Technical interview preparation
Practical skill assessments
Career guidance support
Freshers - 4 LPA to 10 LPA
1-3 Years Experience - 8 LPA to 16 LPA
Senior Professionals - 18 LPA and above
Spark and SQL understanding
Practical project experience
Cloud platform knowledge
Pipeline debugging skills
Real-time data handling ability
Strong project portfolio
Technical interview performance
System design understanding
Junior Data Engineer
Data Engineer
Big Data Engineer
Spark Developer
Cloud Data Engineer
Data Platform Engineer
Data Architect
Cloud Architect
AI infrastructure engineering
Distributed systems management
Cloud architecture roles
Analytics platform engineering
Enterprise data systems
Technical consulting opportunities
Product-based company careers
Startup and independent opportunities
Real project-based learning approach
Live Databricks and Spark practice
Industry-focused cloud training
Practical implementation methods
Resume and portfolio support
Technical interview preparation
Guidance from experienced professionals
Updated syllabus based on 2026 industry needs
Flexible batches for students and working professionals
Placement and career support assistance
we train you to get hired.
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy
Course Design By
Nasscom & Wipro
Course Offered By
Croma Campus
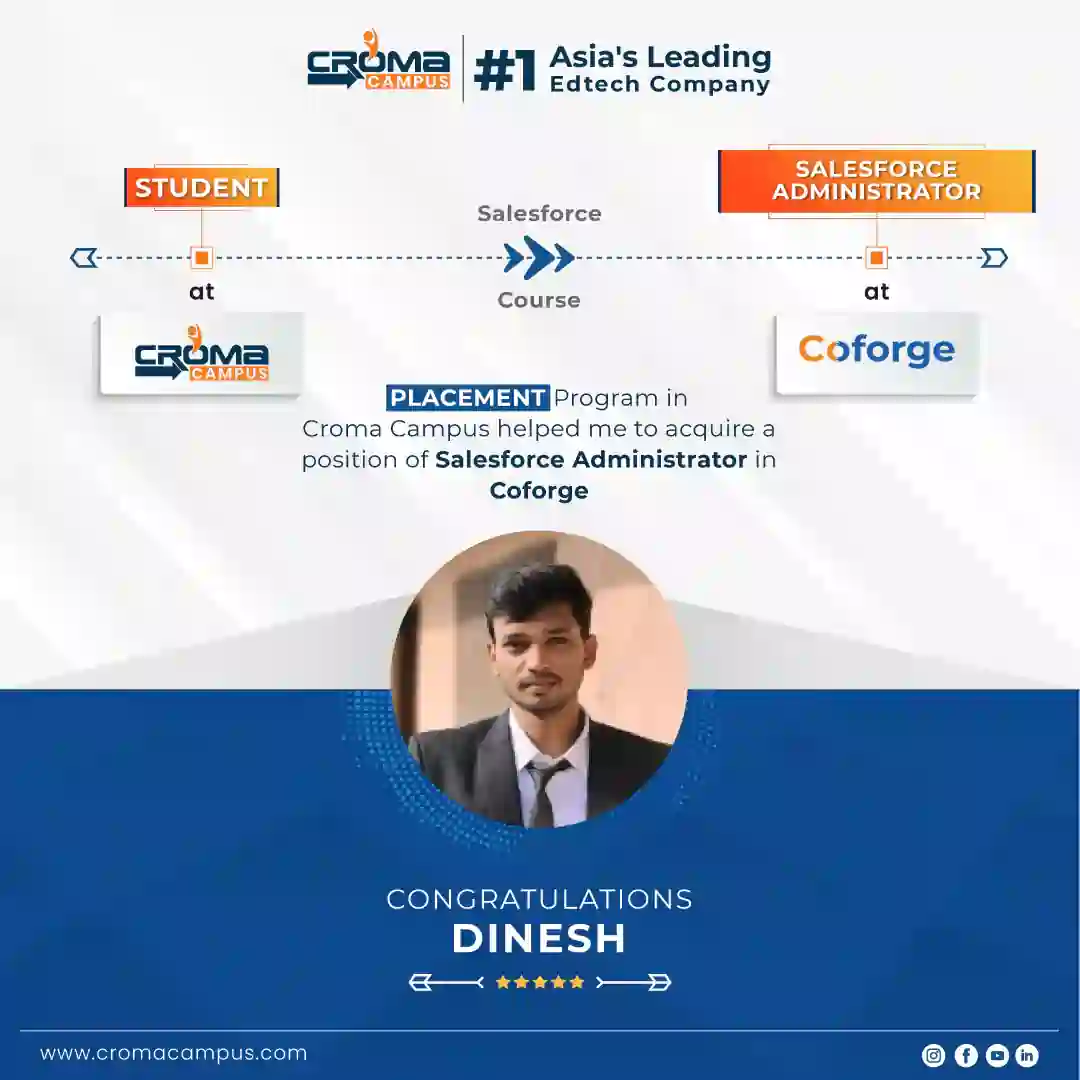
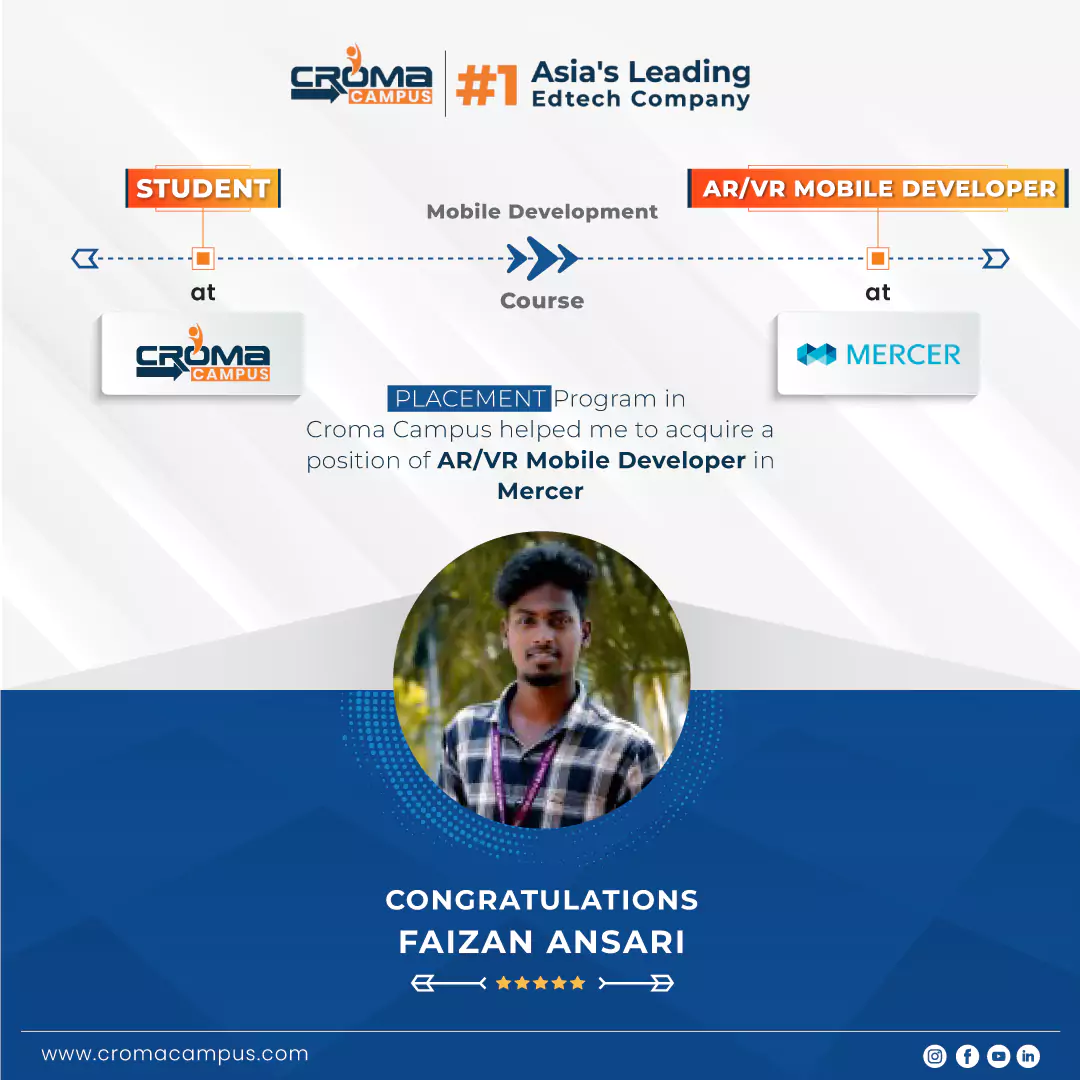
Stories
success
inspiration
career upgrade
career upgrade
career upgrade
career upgrade
You will get certificate after
completion of program
You will get certificate after
completion of program
You will get certificate after
completion of program
in Collaboration with

Empowering Learning Through Real Experiences and Innovation
we train you to get hired.
Phone (For Voice Call):
+91-828 706 0032WhatsApp (For Call & Chat):
+91-828 706 0032Get a peek through the entire curriculum designed that ensures Placement Guidance
Course Design By
Course Offered By
Ready to streamline Your Process? Submit Your batch request today!
Yes, students work on practical ETL pipelines, streaming systems, and cloud-based data engineering projects.
No. Basic computer knowledge and logical understanding are enough to start learning.
Yes, the course includes Azure and AWS Databricks integration and cloud workflow practice.
Yes, Spark is covered in detail including architecture, execution flow, transformations, and optimization.
Yes, cloud data engineering and Databricks skills are highly demanded in 2026.
Yes, mock interviews, resume preparation, and technical discussions are included in the training.

Highest Salary Offered
Average Salary Hike
Placed in MNC’s
Year’s in Training

fast-tracked into managerial careers.
Get inspired by their progress in the
Career Growth Report.
FOR QUERIES, FEEDBACK OR ASSISTANCE
Best of support with us

Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy


For Voice Call
+91-971 152 6942For Whatsapp Call & Chat
+91-9711526942Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!











.webp)























































.webp)



































































































.webp)
.webp)

.png)















