Learn About Machine Learning Fundamentals And Courses For Beginners
4.9 out of 5 based on 5134 votesLast updated on 5th Nov 2023 5.2K Views
- Bookmark

Machine learning basics: algorithms, data, and models. Explore beginner courses to kickstart your journey in this field.

This blog explores the world of Machine Learning, covering its basics, types, and the benefits of a course designed for beginners. Discover key objectives, understand the course duration, and grasp valuable takeaways in your journey into this exciting field.
Overview
What is Machine Learning
Types of Machine Learning
Supervised Machine Learning Techniques
Machine Learning Course for Beginners
Course Objectives
Benefits of taking this Course
Machine Learning Course Duration
Key Takeaways
Overview
Machine Learning, a powerful discipline within artificial intelligence, offers a world of possibilities for beginners. Understanding the core Machine Learning Fundamentals is the foundation for success in this field.
We have designed a Machine Learning Course for Beginners to facilitate your learning journey. This guide will also address the essential aspect of Machine Learning Course Duration. It does not matter whether you are an enthusiast or a professional, let's embark on this educational journey, beginning with the basics.
Machine Learning – Learn Basics with Examples
Machine Learning is a branch of Artificial Intelligence that empowers computers to learn without explicit programming. This concept, introduced by computer scientist Arthur Samuel in 1959, is all about teaching machines to improve their performance based on past experiences. It's like enabling a computer to acquire skills and make predictions for future tasks. Machine Learning aims to reach a level of performance at least comparable to human abilities.
In Technical Terms:
According to Tom M. Mitchell in 1997, Machine Learning occurs when a computer program learns from experience (E) in the context of tasks (T) and performance measures (P). The system's performance in task T, as measured by P, should improve with the accumulation of experience E.
Example: Handwriting Recognition
Consider a handwriting recognition problem where the machine is trained to recognize and classify handwritten words within images. In this scenario:
Task (T): Involves recognizing and classifying handwritten words within images.
Performance Measure (P): This is quantified by the percentage of words correctly classified, also known as accuracy.
Training Experience (E): Comprises a data set of handwritten words with their given classifications.
In the case of this specific task, the machine learns from the provided data set, which is essentially a collection of many examples. Each example consists of a set of features. The more examples it learns from, the better it becomes at recognizing and classifying handwritten words within images.
Machine Learning, in a nutshell, is the art of enabling computers to get better at tasks by learning from their experiences, making it a powerful tool in the world of technology and problem-solving.
You May Also Read: Data Science Qualification
Machine Learning Categories
Machine Learning can be broadly classified into three categories: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning: In supervised learning, the machine is provided with examples that come with labels or target values for each example. These labels are essential for the algorithm to understand the relationships between the features and the desired outcomes.
Classification: In classification tasks, the machine's objective is to predict discrete values. It must determine the most likely category, class, or label for new examples. For instance, it can be used to predict whether a stock's price will rise or fall or classify news articles into categories like politics or leisure.
Regression: In regression problems, the machine predicts the value of a continuous response variable. Examples include forecasting sales for a new product or estimating a job's salary based on its description.
Unsupervised Learning: Unsupervised learning comes into play when the data is unclassified and lacks labeled target values. In this scenario, the system's goal is to uncover hidden patterns within the data. One common task in unsupervised learning is grouping similar examples together, known as clustering.
Reinforcement Learning: Reinforcement learning focuses on goal-oriented algorithms that learn to achieve complex objectives or maximize specific dimensions over multiple steps. This approach enables machines and software agents to autonomously determine the best actions within a given context to optimize their performance. To facilitate this learning, the agent relies on simple reward feedback, often referred to as the reinforcement signal. For example, it can be used to maximize the points earned in a game over multiple moves.
These three categories encompass the core principles of Machine Learning, each serving distinct purposes in solving a wide array of problems and tasks.
Supervised Machine Learning Techniques
In the realm of machine learning, supervised techniques play a pivotal role in predicting values based on known input variables. Among these techniques, two prominent approaches are Linear Regression and Logistic Regression, each designed for distinct prediction tasks. Let's explore the fundamentals and key concepts of these techniques, including the Gradient Descent algorithm, Overfitting/Underfitting, Error Analysis, Regularization, Hyperparameters, and Cross-Validation.
Linear Regression
In linear regression, the primary objective is to predict a real-value variable, denoted as 'y,' from a given set of features represented by 'X.' The relationship between the output and input is linear, defined as ŷ = WX + b.
Here's a breakdown of the elements:
'X' is a vector representing the features of an example.
'W' stands for the weights, a vector of parameters that determine how each feature influences the prediction.
'b' represents the bias term.
The central task is to predict 'y' based on 'X,' to assess the model's performance, we need a measure of accuracy.
Performance Metrics
To evaluate the model's performance, we calculate the error for each example 'i' using the formula:
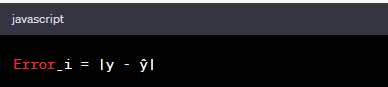
To gauge performance collectively, we calculate the mean of all absolute errors, known as Mean Absolute Error (MAE):
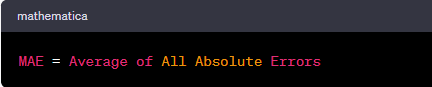
Another widely used metric is Mean Squared Error (MSE), which computes the average of squared differences between predictions and actual observations. The mean is halved (1/2) for computational convenience during the gradient descent.
The primary goal in training a machine learning algorithm is to adjust the weights 'W' to minimize MAE or MSE, effectively reducing errors.
Gradient Descent Algorithm
To achieve this, the model employs the gradient descent algorithm. The algorithm starts with random model parameters and iteratively calculates errors, updating the model parameters to approach values that yield minimal cost.
The critical components of the algorithm include:
The calculation of the gradient of the cost function, represented by the partial derivative of the cost function 'J' with respect to each model parameter 'wj.'
The learning rate 'α,' which controls the speed at which the model converges. A too-large alpha may lead to overshooting, while a too-small alpha results in slower convergence.
You May Also Read: Data Science Course Fees
Gradient descent can be implemented in three ways:
Batch Gradient Descent: Utilizes all training instances to update model parameters in each iteration.
Mini-Batch Gradient Descent: Divides the training set into smaller batches for parameter updates, denoted as 'b.'
Stochastic Gradient Descent (SGD): Updates parameters using a single training instance in each iteration, typically selected randomly.
The choice of gradient descent method depends on the size of the training dataset and the desired convergence speed.
Logistic Regression Made Easy
In certain scenarios, we encounter problems where the outcome isn't like a normal distribution, but rather binary, like a coin toss resulting in heads or tails. Here, we introduce Logistic Regression, a technique that deals with such binary outcomes.
Understanding Binary Outcomes
Imagine a scenario where you want to predict if a student passes or fails an exam. Instead of giving you a percentage, Logistic Regression will tell you the probability of passing. If this probability is equal to or higher than a predefined threshold, say 0.5, we predict a "pass." Otherwise, it's a "fail."
The Sigmoid Function
To achieve this, we use a mathematical function called the Sigmoid Function. This function takes any real number and maps it to a value between 0 and 1. It's like turning any number into a probability. For example, if the Sigmoid Function gives us 0.7, it means there's a 70% chance of success, or a 30% chance of failure.
It's Not Just About Lines
Logistic Regression isn't limited to straight lines. It can model complex relationships, like curves or any other shape, making it versatile for a wide range of problems.
Cost Function and Regularization
When we use the Sigmoid Function, the regular cost function used in linear regression doesn't work. We need a different cost function to ensure we find the best model. This new cost function makes sure the model doesn't get stuck in local optima and is known as the logistic cost function.
Overfitting and Underfitting
Machine learning algorithms need to be just right in terms of complexity. If they are too simple, they underfit the data. If they are too complex, they overfit it. Both situations are not ideal. The goal is to find the sweet spot that fits just right.
Regularization to the Rescue
To control the model's complexity, we use a technique called Regularization. It adds a penalty term to the error function, discouraging weights from becoming too large.
Hyperparameters and Cross-Validation
Before we even start training, we must decide on some "higher-level" parameters known as hyperparameters. These include things like learning rate and regularization strength.
Logistic Regression is a powerful tool to predict binary outcomes. It doesn't just rely on straight lines but can model more complex relationships. Using the Sigmoid Function, it calculates probabilities, making it a versatile choice for various scenarios. By carefully adjusting hyperparameters and using cross-validation, we can harness the full potential of Logistic Regression in solving real-world problems.
With this discussion, you have a clear idea of machine learning fundamentals and applications of machine learning. Now let us see the machine learning course for beginners and the duration of the course.
Basics of Machine Learning Certification Course for Beginners:
This is the most common machine learning course for beginners available with top IT training companies like Croma Campus or more. The course begins by introducing you to the fundamental concepts of Machine Learning, helping you grasp its algorithms and explore its real-world applications. You'll delve into the mathematical underpinnings that drive Machine Learning, laying a strong foundation for your learning adventure.
As you progress, you'll unravel crucial concepts, including supervised Machine Learning, linear regression, Pearson's coefficient, best-fit line, and coefficient of determinant. These building blocks will empower you to understand Machine Learning on a deeper level and apply it effectively.
To reinforce your newfound knowledge, we'll take you through a compelling case study, bringing these concepts to life in a practical context. By enrolling in this free Basics of Machine Learning Course and successfully completing the quiz at the end, you'll earn a valuable certificate, validating your expertise in this exciting field.
If you aspire to carve a career in Machine Learning, our comprehensive Machine Learning course is your ultimate companion. Join this esteemed professional program and obtain a certificate that showcases your skills and opens doors to exciting opportunities. Your journey into the world of Machine Learning starts here.
What You Will Learn in the Basics of Machine Learning Course?
Introduction to Machine Learning - Gain a solid understanding of what Machine Learning is all about, its core principles, applications, and the impact it has on various industries.
Supervised Machine Learning - Dive into the world of supervised learning, and understand how it works and its real-world applications.
Linear Regression - Explore the concept of linear regression, a key technique in Machine Learning. Learn how it's used to make predictions and analyze data.
Pearson's Coefficient - Delve into statistical analysis with a focus on Pearson's coefficient. Understand how it measures the strength and direction of the linear relationship between two variables.
Coefficient of Determinant - Explore the coefficient of determination, a vital metric that assesses the goodness of fit in regression models. Learn how it helps you evaluate the accuracy of your predictions.
You May Also Read:
Data Science Interview Questions And Answers
Artificial Intelligence and Machine Learning
Machine Learning and Deep Learning
Machine Learning Interview Questions and Answers
Benefits of Taking this Course:
Fundamental Knowledge: This course provides you with a strong foundation in Machine Learning, making it an ideal starting point for your learning journey.
Practical Skills: You'll gain practical skills in supervised learning, linear regression, and statistical analysis, which are valuable in various industries.
Real-World Applications: Understand how Machine Learning is applied in real-world scenarios, giving you insights into its wide-ranging utility.
Statistical Proficiency: Master statistical concepts like Pearson's coefficient and the coefficient of determinant, enhancing your data analysis abilities.
Case Study: Benefit from a practical case study that illustrates how these concepts are applied, reinforcing your understanding.
Certificate: By completing the course and the quiz, you'll earn a certificate, showcasing your expertise and commitment to advancing your knowledge.
Career Advancement: If you aspire to build a career in Machine Learning, this course is a stepping stone toward your professional goals.
Machine Learning Course Duration
The duration of the "Basics of Machine Learning" course can vary depending on the platform or institution offering it. Typically, introductory or basic Machine Learning courses are designed to be relatively short and flexible to accommodate different learning paces. They can range from a few hours to a few weeks, and some may even be self-paced, allowing you to complete the course at your own speed.
To get the specific duration of this course, you should refer to the course description or syllabus provided by the platform or institution where you plan to enroll. This will give you accurate information about the estimated duration and the course structure.
Enroll in the "Basics of Machine Learning" course today to gain essential skills and knowledge that can open doors to a rewarding career in this dynamic field.
Subscribe For Free Demo
Free Demo for Corporate & Online Trainings.
Course Features
RELATED BLOGS

How Many Types of AI in 2026? Complete Guide with AI Interview Question

How Does AI (Artificial Intelligence) Work? Explained Simply

What Skills Separate Beginner And Advanced Data Science Experts?

How To Crack Artificial Intelligence Interviews? Q&A Guide 2026

Best Tools And Technologies For Data Science 2026
.webp)
How Will AI In 2026 Transform Industries With Emerging Tools?

Most Popular Data Science Interview Questions And Answers For 2026

What Is Hierarchical Clustering In Machine Learning?

The Future Is Now: Key Things To Know About AI In 2026

What Is The Difference Between ML Vs DL?

Advantages Of Data Science In Python













.webp)
.webp)

.png)















