



















 Career Transition
Career Transition Career Gap
Career Gap Placement Activities
Placement Activities Placement Drives
Placement Drives Latest Hiring
Latest Hiring

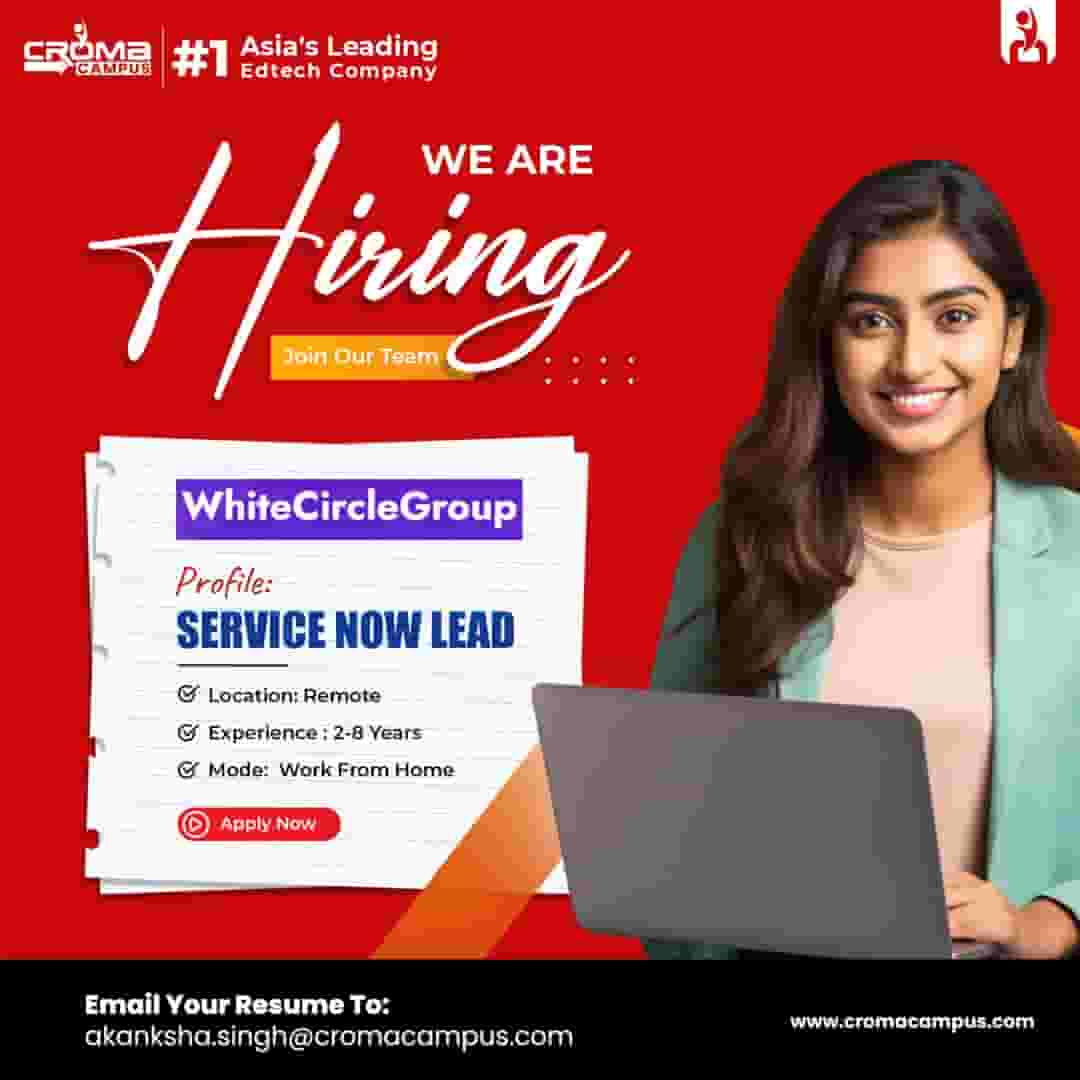


.jpg)






Course Design By
Nasscom & Wipro
Master the key concepts of Hadoop and Big data. Join and learn from a Big Data/Hadoop expert.
In collaboration with

Online/Offline
Format
LMS
Life Time Access
we train you to get hired.

At the initial level of the course, our trainers will help you know its basic fundamentals.
Further, you will also receive sessions concerning Hadoop Architecture Distributed Storage (HDFS) and YARN, What Is HDFS, Need for HDFS, Need for HDFS, etc.
Our trainers will also help you know the whole Data Replication Topology, HDFS Command Line, command line, Data Ingestion into Big Data Systems and ETL, distributed processing, Hive SQL over Hadoop MapReduce, basics of Functional Programming and Scala, etc.
Here, you will also get a chance to imbibe new skills concerning Big Data Hadoop Training in Noida.
In a nutshell, we can say, you will end up imbibing every detail of this course in a detailed manner.
At the initial level, you will make around Rs. 3 Lakh to Rs. 3.5 Lakh, which is quite good for freshers.
Likewise, an experienced Big Data Hadoop Developer earns Rs. 11.5 Lakh annually.
Moreover, by obtaining more work experience along with the latest skills, and trends your salary structure will expand.
By working as a freelancer, you will make some good additional income also.
By obtaining for its legit training from a reputed educational foundation, you will turn into a knowledgeable Big Data Hadoop Developer.
Well, withholding a proper accreditation of Big Data Hadoop Developer, you will be offered an excellent salary package right from the beginning of your career.
Getting to know each side of Big Data Hadoop will also push you forward to come up with innovative applications.
Knowing about Big Data Hadoop Training in Noida will eventually enhance your resume.
You will always have numerous jobs offers in hand.
Firstly, you will have to build, imply and maintain Big Data solutions.
In fact, you will also have to execute database modeling and development, data mining, and warehousing.
You will also have to design and deploy data platforms across numerous domains assuring operability.
Our trainers will also help you to experience the Hadoop ecosystem (HDFS, MapReduce, Oozie, Hive, Impala, Spark, Kerberos, KAFKA, etc.).
At the same time, you will also have to transform data for meaningful analyses and enhance data efficiency.
Often you will have to execute the testing scripts and analyze the results.
By getting started with this specific course, you will end up strengthening your base knowledge.
You will know the various features and offerings of this technology by getting in touch with a well-established Big Data Hadoop Training Institute in Noida.
You will also know about building a new sort of application and implying some latest features.
You will end up obtaining some untold, and hidden facts from the Big Data Hadoop Training in Noida respectively.
By joining Croma Campus, you will get the opportunity to get placed in your choice of companies post enrolling with the Big Data Hadoop course.
Our trainers will also help you in building an impressive resume.
They will also suggest you some effective tips to pass the interviews.
we train you to get hired.
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy
+ More Lessons
Course Design By
Nasscom & Wipro
Course Offered By
Croma Campus
Stories
success
inspiration
career upgrade
career upgrade
career upgrade
career upgrade
You will get certificate after
completion of program
You will get certificate after
completion of program
You will get certificate after
completion of program
in Collaboration with

Empowering Learning Through Real Experiences and Innovation
we train you to get hired.
Phone (For Voice Call):
+91-828 706 0032WhatsApp (For Call & Chat):
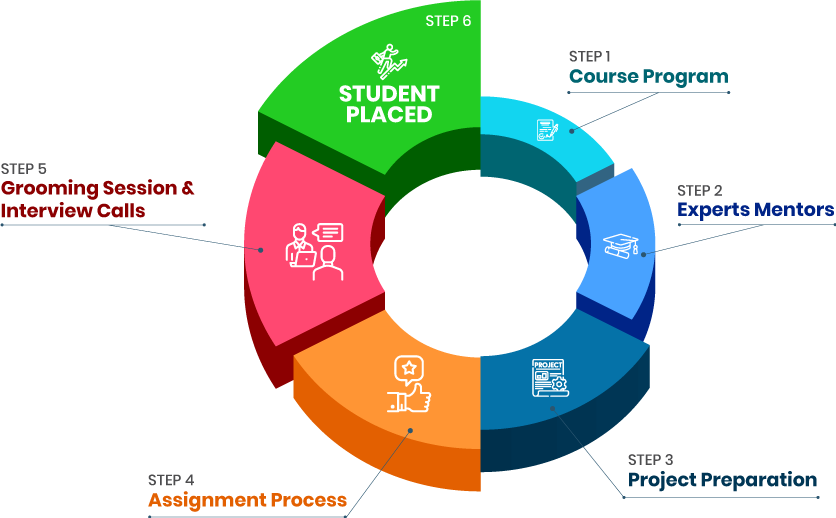
+91-828 706 0032Get a peek through the entire curriculum designed that ensures Placement Guidance
Course Design By
Course Offered By
Ready to streamline Your Process? Submit Your batch request today!
Our training programs will enable professionals to secure placements in MNCs. Croma Campus is one of the most recommended Big Data Hadoop Training Institute in Noida that offers hands on practical knowledge / practical implementation.
The need of Its professionals is increasing so Hadoop is one of the better choices for career growth and enough income Apache Hadoop provides you the better package.
Join an institute who provides the best trainer and training as well. Like Croma Campus, training programs are based on current industry standards.
Industry standard projects are included in our training programs and Live Project based training with trainers having 5 to 15 years of Industry Experience.
There are two ways of payment, one is digital payment like NEFT, GOOGLE PAY or PATYM and the second one CASH.
Any Body who Graduated, Post Graduated, Fresher or Professionals who want to quick start their career in BIG DATA HADOOP Field.
You just need to select the best institute wisely So that you can learn the latest Module in a particular course.
The duration is depending on your selection of training mode like classroom training, online training or fast track training. For fee structure you can contact us at: 9711526942.
The best way to obtain its information is to get in touch with an educational foundation.
Yes, it's hugely in demand, and getting acquainted with its information will help you grow in this field.
A skilled Big Data Hadoop Developer earns around ₹ 13.5 Lakhs to ₹ 15.5 Lakhs based on their experience.
For details information & FREE demo class call us on +91-9711526942 or write to us info@cromacampus.com
Address: - G-21, Sector-03, Noida (201301)

Highest Salary Offered
Average Salary Hike
Placed in MNC’s
Year’s in Training

fast-tracked into managerial careers.
Get inspired by their progress in the
Career Growth Report.
FOR QUERIES, FEEDBACK OR ASSISTANCE
Best of support with us

Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!
By registering here, I agree to Croma Campus Terms & Conditions and Privacy Policy


For Voice Call
+91-971 152 6942For Whatsapp Call & Chat
+91-9711526942Share some of your details and we will be in touch with you for demo details, and know about Batches Available with us!











.webp)























































.webp)











































































.webp)
.webp)
























.webp)
.webp)

.png)















